The Experiment
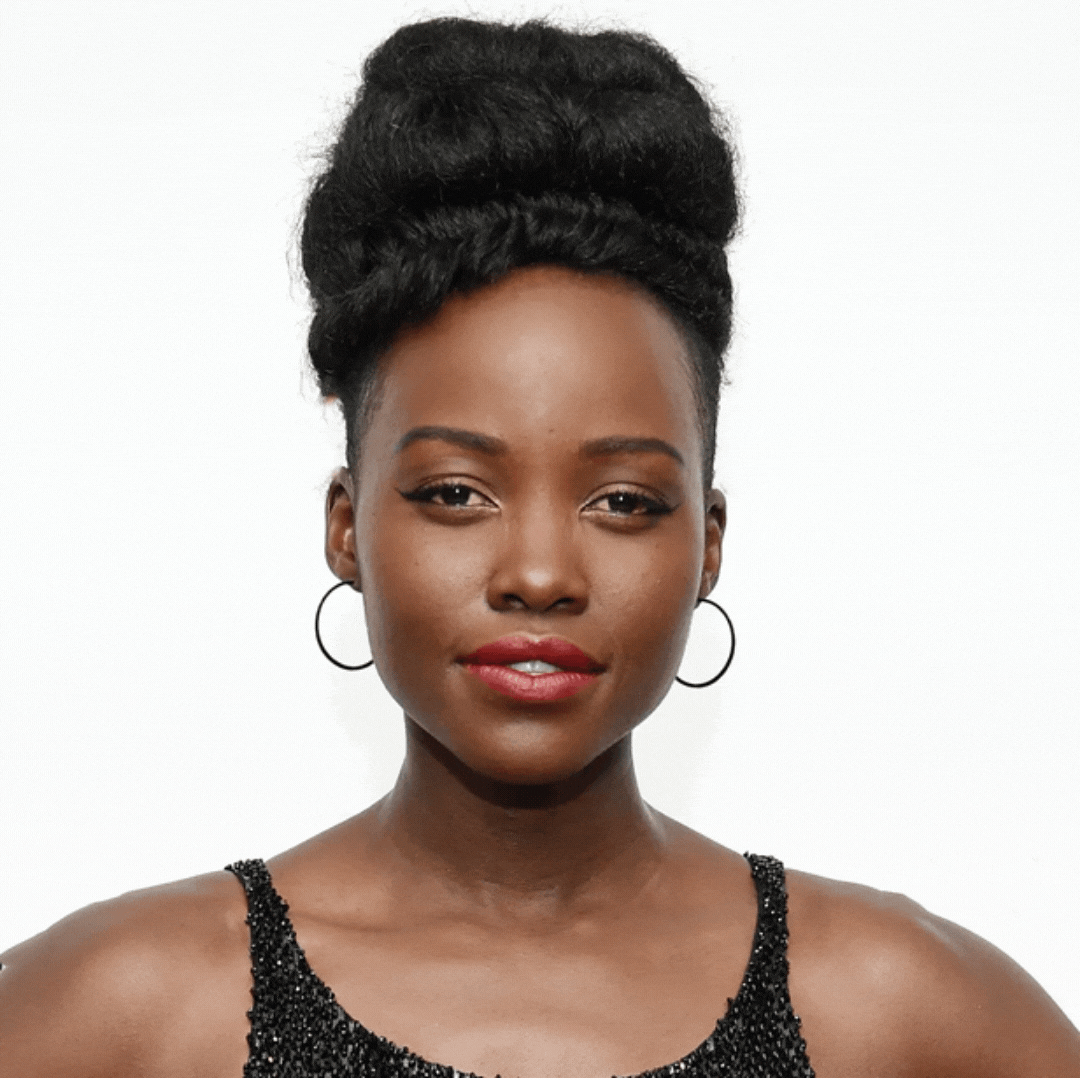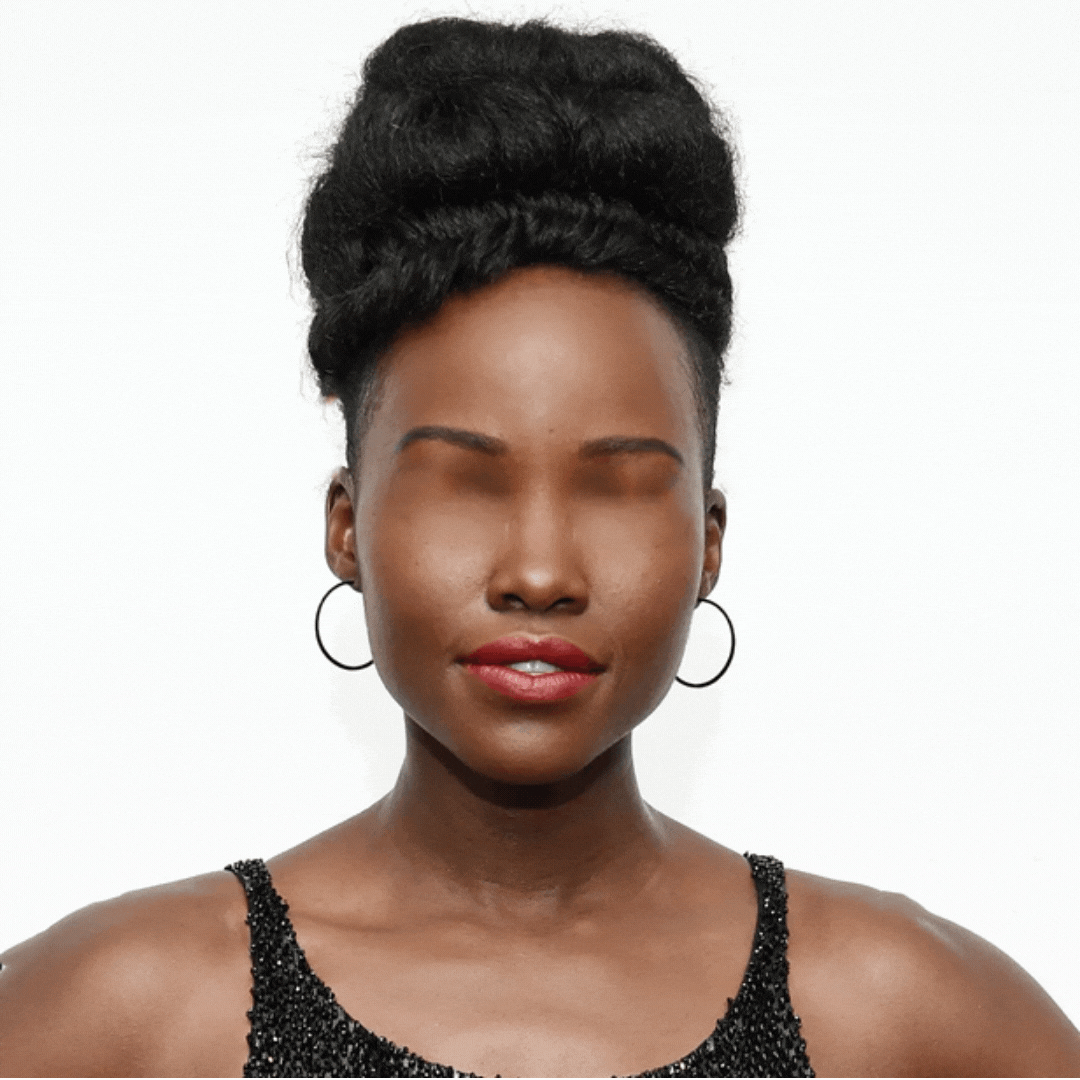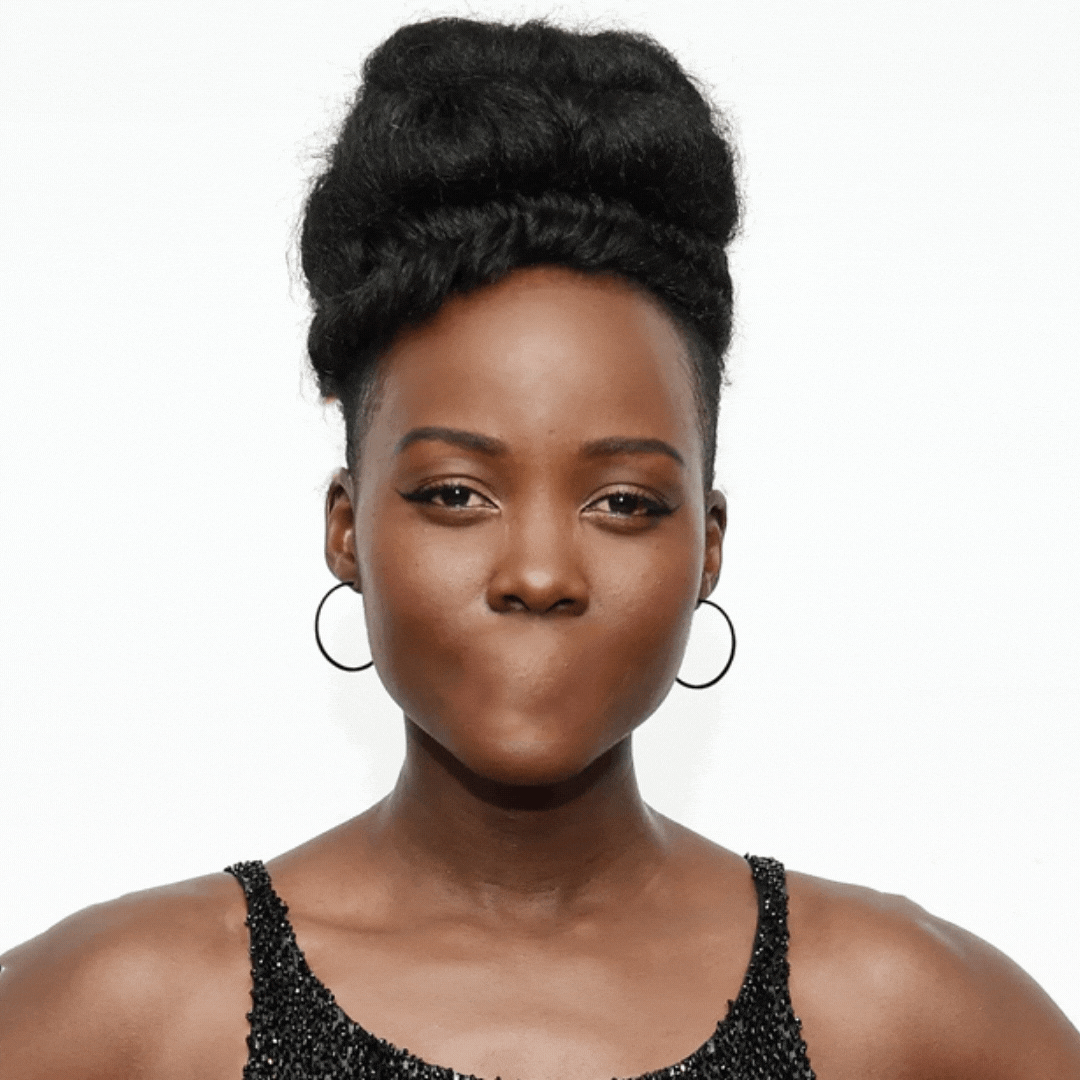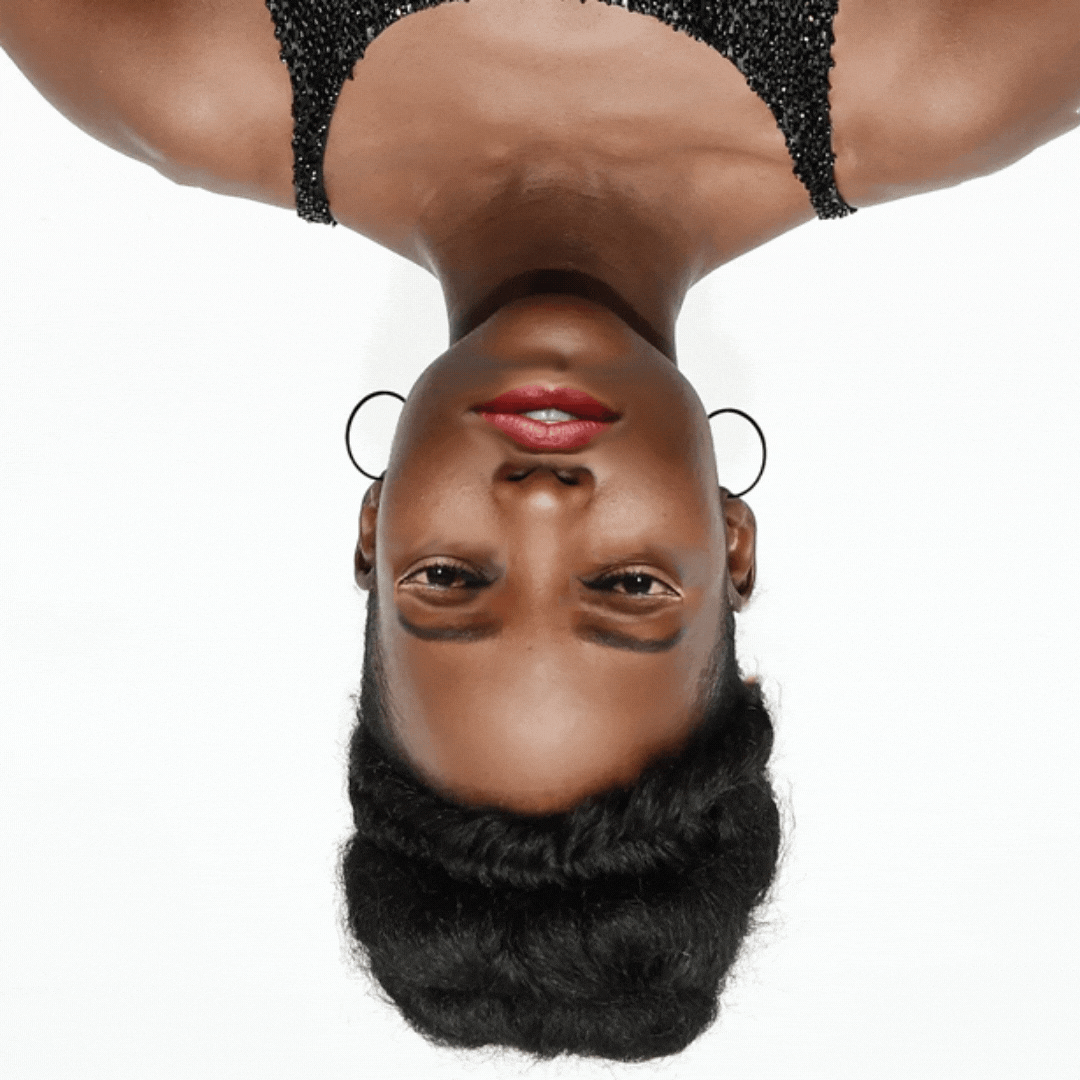
Part I: Controlled Single-Face Variations
Variations include: inverted face, one-eyed, no eyes, no nose, no mouth, no hair, inverted features, inverted features and face.

Part II: Diverse-Face Variations
Using one face as anchor, we compare diverse faces against similar variations of specific features, such as eyes, nose and hair.
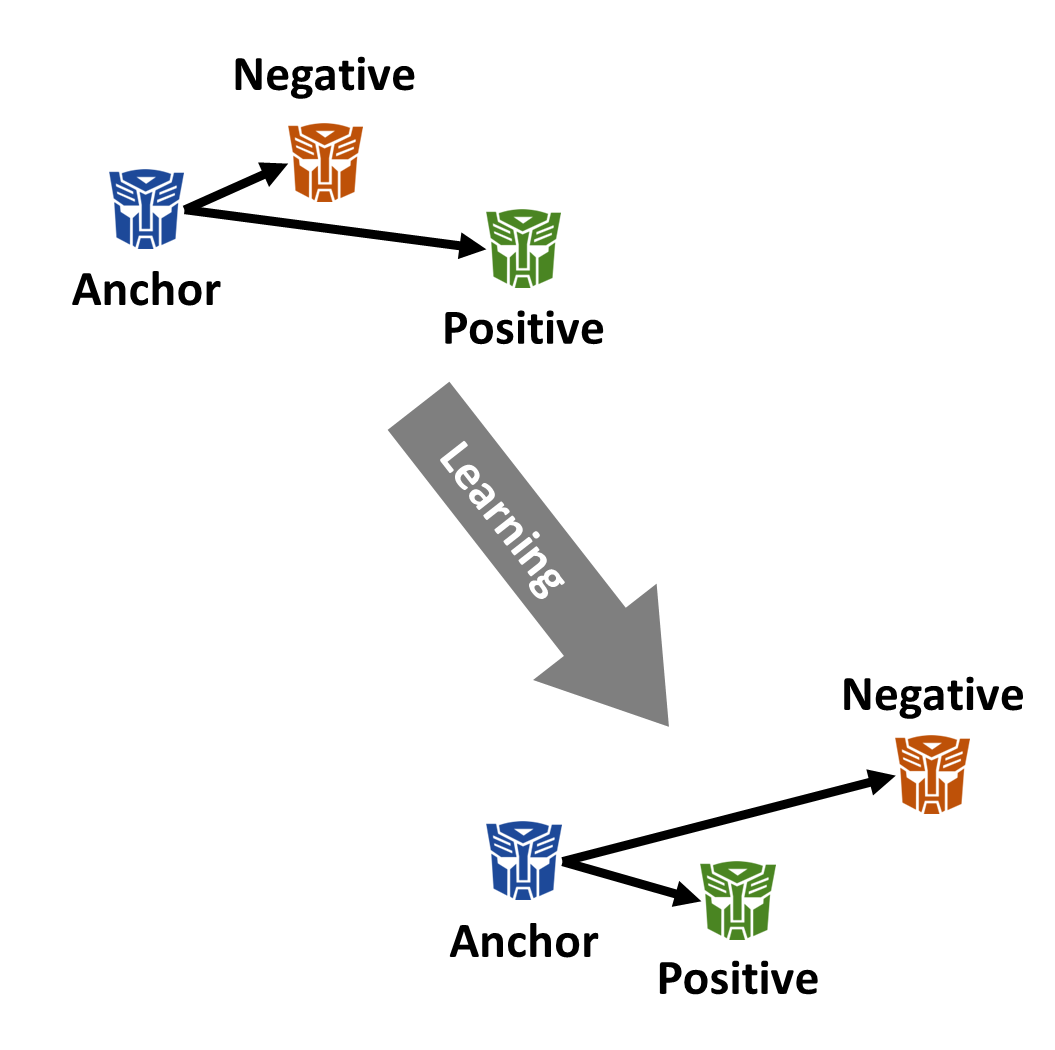
Part III: Results and Discussion
Hypothesis is rejected: Face Transformer is less likely to holistically recognize and identify faces than FaceNet.